逻辑回归
本次作业的目的是建立一个逻辑回归模型,用于预测一个学生是否应该被大学录取。
简单起见,大学通过两次考试的成绩来确定一个学生是否应该录取。你有以前数届考生的成绩,可以做为训练集学习逻辑回归模型。每个训练样本包括了考生两次考试的成绩和对应的录取决定。
你的任务是建立一个分类模型,根据两次考试的成绩来估计考生被录取的概率。
本次实验需要实现的函数
plot_data绘制二维的分类数据。sigmoid函数cost_function逻辑回归的代价函数cost_gradient逻辑回归的代价函数的梯度,无正则化predict逻辑回归的预测函数cost_function_reg逻辑回归带正则化项的代价函数cost_gradient_reg逻辑回归的代价函数的梯度,带正则化
1 | # 导入需要用到的库 |
数据可视化
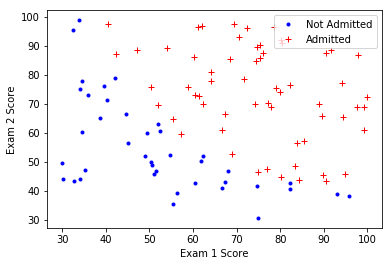
在实现机器学习算法前,可视化的显示数据以观察其规律通常是有益的。本次作业中,你需要实现 plot_data 函数,用于绘制所给数据的散点图。你绘制的图像应如下图所示,两坐标轴分别为两次考试的成绩,正负样本分别使用不同的标记显示。
1 | def plot_data(X, y): |
调用 plot_data,可视化第一个文件LR_data1数据。绘制的图像如下:‘

1 | # 加载数据 注意使用 !ls 或 !find 命令确定数据文件所在的目录 dataXXXX 。 |
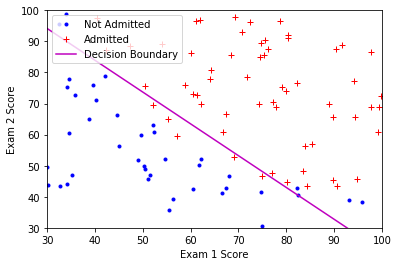
绘制分类面
1 | def plot_decision_boundary(theta, X, y): |
热身练习:Sigmoid函数
逻辑回归的假设模型为:
其中函数 $g(\cdot)$ 是Sigmoid函数,定义为:
本练习中第一步需要你实现 Sigmoid 函数。在实现该函数后,你需要确认其功能正确。对于输入为矩阵和向量的情况,你实现的函数应当对每一个元素执行Sigmoid 函数。
1 | def sigmoid(z): |
1 | # 测试 sigmoid 函数 |
Value of sigmoid at [-10, -5, 0, 5, 10] are:
[4.53978687e-05 6.69285092e-03 5.00000000e-01 9.93307149e-01
9.99954602e-01]
代价函数与梯度
现在你需要实现逻辑回归的代价函数及其梯度。补充完整cost_function函数,使其返回正确的代价。补充完整cost_gradient函数,使其返回正确的梯度。
逻辑回归的代价函数为:
对应的梯度向量各分量为
1 | def cost_function(theta, X, y): |
1 | def cost_gradient(theta, X, y): |
预测函数
在获得模型参数后,你就可以使用模型预测一个学生能够被大学录取。如果某学生考试一的 成绩为45,考试二的成绩为85,你应该能够得到其录取概率约为0.776。
你需要完成 predict 函数,该函数输出“1”或“0”。通过计算分类正确的样本百分数, 我们可以得到训练集上的正确率。
1 | def predict(theta, X): |
使用scipy.optimize.fmin_cg学习模型参数
在本次作业中,希望你使用 scipy.optimize.fmin_cg 函数实现代价函数 $J(\theta)$ 的优化,得到最佳参数 $\theta^{*}$ 。
使用该优化函数的代码已经在程序中实现,调用方式示例如下:1
2
3
4
5
6
7
8ret = op.fmin_cg(cost_function,
theta,
fprime=cost_gradient,
args=(X, y),
maxiter=400,
full_output=True)
theta_opt, cost_min, _, _, _ = ret
其中cost_function为代价函数, theta 为需要优化的参数初始值, fprime=cost_gradient 给出了代价函数的梯度, args=(X, y) 给出了需要优化的函数与对应的梯度计算所需要的其他参数, maxiter=400 给出了最大迭代次数, full_output=True 则指明该函数除了输出优化得到的参数 theta_opt 外,还会返回最小的代价函数值 cost_min 等内容。
对第一组参数,得到的代价约为 0.203 (cost_min)。
1 | def logistic_regression(): |
Cost at initial theta (zeros): nan
Gradient at initial theta (zeros): [ 0.4 20.81292044 21.84815684]
Optimization terminated successfully.
Current function value: 0.203498
Iterations: 37
Function evaluations: 111
Gradient evaluations: 111
theta_op:
[-25.15777637 0.20620326 0.20144282]
For a student with scores 45 and 85, we predict an admission probability of: 0.7762612158589474
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/ipykernel_launcher.py:7: RuntimeWarning: divide by zero encountered in log
import sys
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/ipykernel_launcher.py:7: RuntimeWarning: invalid value encountered in multiply
import sys
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/ipykernel_launcher.py:8: RuntimeWarning: overflow encountered in exp
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/ipykernel_launcher.py:8: RuntimeWarning: overflow encountered in exp
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/ipykernel_launcher.py:7: RuntimeWarning: divide by zero encountered in log
import sys
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/ipykernel_launcher.py:7: RuntimeWarning: invalid value encountered in multiply
import sys
正则化的逻辑回归
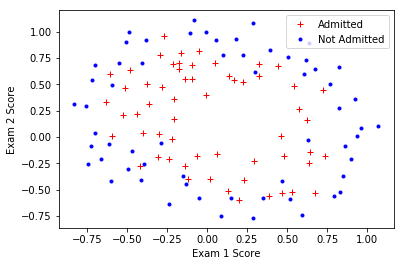
数据可视化
调用函数plot_data可视化第二组数据 LR_data2.txt 。
正确的输出如下:

1 | # 加载数据 |
特征变换
创建更多的特征是充分挖掘数据中的信息的一种有效手段。在函数 map_feature 中,我们将数据映射为其六阶多项式的所有项。

1 | def map_feature(X1, X2, degree=6): |
代价函数与梯度
逻辑回归的代价函数为
对应的梯度向量各分量为:
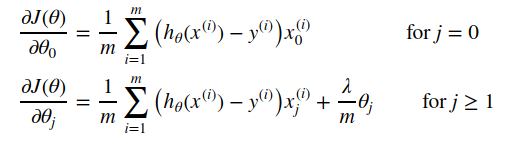
完成以下函数:
cost_function_reg()cost_gradient_reg()
1 | def cost_function_reg(theta, X, y, lmb): |
模型训练
如果将参数$\theta$ 初始化为全零值,相应的代价函数约为 0.693。可以使用与前述无正则化项类似的方法实现梯度下降,
获得优化后的参数 $\theta^{*}$ 。
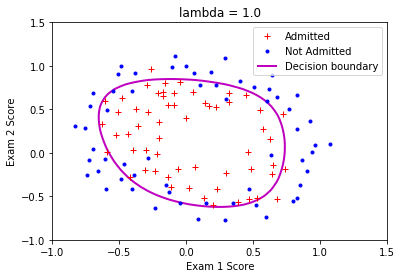
你可以调用 plot_decision_boundary 函数来查看最终得到的分类面。建议你调整正则化项的系数,分析正则化对分类面的影响!
参考输出图像:

1 | def logistic_regression_reg(lmb=1.0): |
(118, 28)
Cost at initial theta (zeros): 0.6931471805599454
Gradient at initial theta (zeros):
[8.47457627e-03 1.87880932e-02 7.77711864e-05 5.03446395e-02
1.15013308e-02 3.76648474e-02 1.83559872e-02 7.32393391e-03
8.19244468e-03 2.34764889e-02 3.93486234e-02 2.23923907e-03
1.28600503e-02 3.09593720e-03 3.93028171e-02 1.99707467e-02
4.32983232e-03 3.38643902e-03 5.83822078e-03 4.47629067e-03
3.10079849e-02 3.10312442e-02 1.09740238e-03 6.31570797e-03
4.08503006e-04 7.26504316e-03 1.37646175e-03 3.87936363e-02]
Warning: Desired error not necessarily achieved due to precision loss.
Current function value: 0.535776
Iterations: 8
Function evaluations: 75
Gradient evaluations: 65
theta_op:
[ 1.22008591 0.6174169 1.18134764 -1.96102914 -0.84518957 -1.23644428
0.09323171 -0.35130743 -0.35278837 -0.19758548 -1.46793288 -0.09276645
-0.57816353 -0.25825218 -1.18239765 -0.27467132 -0.21615072 -0.06863601
-0.25974267 -0.28202028 -0.56424266 -1.07964814 -0.0090027 -0.28241083
-0.00667624 -0.31162077 -0.13714068 -1.03061176]
Train Accuracy: 49.87072680264292